Machine Learning in Quant: Promise & Peril
Where machine learning genuinely helps a quant, where it quietly leaks the future, and how to use it safely.
- ·Where ML helps vs hurts
- ·Feature & label leakage
- ·Train/test on time series
- ·Meta-labeling
- ·Feature importance
- ·Avoiding overfit ML
Machine learning is the most hyped and most misunderstood tool in modern trading. The pitch is seductive: feed a powerful model enough data and it will discover patterns no human could see. The reality, in markets, is harsher - ML is brilliant at finding patterns that aren't there, fitting noise so convincingly that it fools its own creator. Used carelessly (which is how it's usually used), it's a faster, more sophisticated way to overfit. Used with discipline, it has a real but narrow place. This chapter shows you both, honestly.
The honest experiment
Let's just try it. We'll build sensible features from past returns, momentum and volatility, and train a random forest to predict whether Nifty rises tomorrow - with a strict time-ordered split, no peeking:
# Can ML predict tomorrow's direction? Train honestly on time-ordered data and see.
import os
from datetime import datetime
import pandas as pd
from openalgo import api
from sklearn.ensemble import RandomForestClassifier
client = api(
api_key=os.getenv("OPENALGO_API_KEY", "your_api_key_here"),
host=os.getenv("OPENALGO_HOST", "http://127.0.0.1:5000"),
)
end = datetime.now().strftime("%Y-%m-%d")
c = client.history(symbol="NIFTY", exchange="NSE_INDEX", interval="D",
start_date="2019-01-01", end_date=end)["close"]
r = c.pct_change()
df = pd.DataFrame(index=c.index)
for lag in [1, 2, 3, 5]:
df[f"ret{lag}"] = r.shift(lag) # only PAST returns as features
df["mom10"] = c.pct_change(10).shift(1)
df["vol10"] = r.rolling(10).std().shift(1)
df["target"] = (r.shift(-1) > 0).astype(int) # did tomorrow go up?
df = df.dropna()
X, y = df.drop(columns="target"), df["target"]
split = int(len(df) * 0.7) # time-ordered split - NEVER shuffle a time series
model = RandomForestClassifier(n_estimators=200, max_depth=5, random_state=0)
model.fit(X[:split], y[:split])
train_acc = model.score(X[:split], y[:split]) * 100
test_acc = model.score(X[split:], y[split:]) * 100
baseline = max(y[split:].mean(), 1 - y[split:].mean()) * 100
print(f"Train accuracy : {train_acc:.1f}%")
print(f"Test accuracy (out-of-sample): {test_acc:.1f}%")
print(f"Baseline (always guess majority): {baseline:.1f}%")
print("\nHigh train, ~coin-flip test = the model memorised noise. Direction resists ML prediction.")Train accuracy : 69.1% Test accuracy (out-of-sample): 50.1% Baseline (always guess majority): 51.2% High train, ~coin-flip test = the model memorised noise. Direction resists ML prediction.
Read those three numbers and feel the disappointment that every quant must internalise. The model hit 69% on the training data - it looks like it learned something. But on the out-of-sample test it scored 50% - a coin flip - and actually below the 51% you'd get by blindly guessing the majority class. The 69% was pure illusion: the model memorised the noise of the training period, which tells you nothing about tomorrow. A powerful algorithm, sensible features, clean code - and zero predictive edge on direction.
The overfit gap
The danger gets worse the more powerful the model. Let the trees grow deeper and watch the gap between training and reality explode:
# The overfit gap: train accuracy soars, test accuracy sits at a coin flip.
import os
from datetime import datetime
from pathlib import Path
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from openalgo import api
from sklearn.ensemble import RandomForestClassifier
client = api(
api_key=os.getenv("OPENALGO_API_KEY", "your_api_key_here"),
host=os.getenv("OPENALGO_HOST", "http://127.0.0.1:5000"),
)
end = datetime.now().strftime("%Y-%m-%d")
c = client.history(symbol="NIFTY", exchange="NSE_INDEX", interval="D",
start_date="2019-01-01", end_date=end)["close"]
r = c.pct_change()
df = pd.DataFrame(index=c.index)
for lag in [1, 2, 3, 5]:
df[f"ret{lag}"] = r.shift(lag)
df["mom10"] = c.pct_change(10).shift(1)
df["vol10"] = r.rolling(10).std().shift(1)
df["target"] = (r.shift(-1) > 0).astype(int)
df = df.dropna()
X, y = df.drop(columns="target"), df["target"]
split = int(len(df) * 0.7)
# The deeper the trees, the more the model memorises - and the wider the overfit gap.
rows = []
for depth in [2, 5, 10, 20]:
m = RandomForestClassifier(n_estimators=200, max_depth=depth, random_state=0).fit(X[:split], y[:split])
rows.append({"depth": str(depth), "set": "train", "acc": m.score(X[:split], y[:split]) * 100})
rows.append({"depth": str(depth), "set": "test", "acc": m.score(X[split:], y[split:]) * 100})
data = pd.DataFrame(rows)
sns.set_theme(style="whitegrid")
fig, ax = plt.subplots(figsize=(8, 4.5))
sns.barplot(data=data, x="depth", y="acc", hue="set",
palette={"train": "#dc2626", "test": "#16a34a"}, ax=ax)
ax.axhline(50, color="#555", ls="--", lw=1, label="coin flip (50%)")
ax.set_title("ML overfit gap - train accuracy climbs, test stays at chance")
ax.set_xlabel("Tree depth (model complexity)")
ax.set_ylabel("Accuracy (%)")
ax.legend()
out = Path(__file__).with_suffix(".png")
plt.savefig(out, dpi=110, bbox_inches="tight")
print(f"Deepest model: train {data.iloc[-2]['acc']:.0f}% vs test {data.iloc[-1]['acc']:.0f}%. Saved {out.name}")Deepest model: train 100% vs test 49%. Saved 02_ml_overfit.png
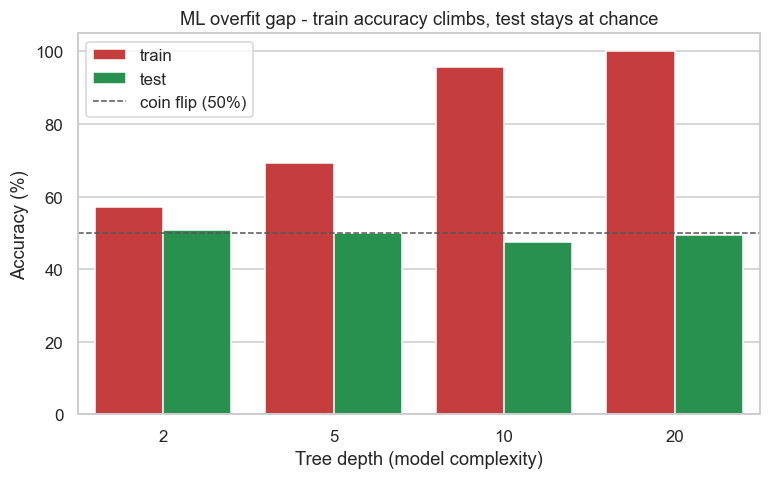
At the deepest setting the model scores a perfect 100% on training and 49% on test. That's the signature of overfitting in one chart: more complexity makes training accuracy soar and out-of-sample accuracy stay pinned at chance. In a low-signal domain like markets, model power is a liability - it just lets the model memorise more noise. This single picture should make you suspicious of any complex ML strategy that doesn't show its out-of-sample numbers.
Where ML helps and where it hurts
So is ML useless for quants? No - but you have to point it at the right problems:
ML shines at combining many weak signals into one, capturing nonlinear interactions a linear model misses, forecasting volatility (which, unlike direction, has real structure - Chapter 16), and digesting alternative data like news text. It fails - dangerously - at predicting raw direction in low-signal data, exactly where beginners point it first.
Leakage: the silent killer
Beyond overfitting, ML in finance has a uniquely treacherous bug: leakage - information from the future sneaking into training. It hides in subtle places: a feature computed using data from after the prediction point; overlapping labels (predicting 5-day returns on daily data so consecutive samples share days); or preprocessing leakage - scaling or selecting features using statistics from the whole dataset, including the test set. Each one inflates your backtest and vanishes in live trading. Leakage is to ML what look-ahead (Chapter 32) is to backtesting - the same disease, more places to hide.
Time-series validation, never random shuffle
The cardinal rule follows directly: never shuffle a financial time series. Standard ML cross-validation randomly shuffles data - catastrophic here, because it lets the model train on days that come after the days it's tested on, a built-in leak. Use walk-forward validation (Chapter 32) or its rigorous cousin, purged cross-validation, which deliberately removes overlapping samples around each test window. Time order is sacred.
Meta-labeling: ML's best trick
The most successful way quants actually use ML isn't to predict direction at all - it's meta-labeling. Let a simple, economically-grounded model generate the primary signal (which way to trade), and let ML answer a narrower, easier question: should I take this trade, and how big? ML is far better at filtering and sizing - separating the high-conviction setups from the marginal ones - than at calling direction from scratch. Use it as a risk manager and filter, not an oracle.
In markets, model power is usually a liability - it overfits noise (train 100%, test 49%). ML's real value is narrow: combining weak signals, modelling volatility, processing alt-data, and meta-labeling (sizing a signal, not predicting direction). Always validate time-ordered, hunt relentlessly for leakage, and demand an economic reason - exactly as you would for any other strategy.
Try it yourself
- Shuffle the train/test split (the wrong way) and watch the test accuracy jump - proof of why time order matters.
- Point the model at volatility instead of direction (predict whether tomorrow's |return| is large). Does ML do better on the predictable target?
- Strip the model back to a single feature and a depth-2 tree. Does the smaller model's test accuracy actually improve?
Recap
- ML is brilliant at fitting noise: a random forest hit 69% (then 100%) in training but 50% / 49% out-of-sample - no edge on direction.
- More model complexity widens the overfit gap in low-signal markets - power is a liability, not an asset.
- ML helps with combining weak signals, nonlinear patterns, volatility forecasting and alt-data; it hurts at predicting raw direction.
- Leakage (future info, overlapping labels, preprocessing on full data) is the silent killer - validate time-ordered, never shuffle, use purged CV.
- The best practical use is meta-labeling - ML filters and sizes an economically-grounded signal rather than predicting direction from scratch.
ML, used well, needs clean, point-in-time, well-organised data - which brings us to the unglamorous backbone of all quant work. Next: data and research infrastructure, the plumbing that turns ideas into reproducible results.