Monitoring, Reconciliation and Incident Handling
Keeping a live book honest and alive - real-time monitoring, end-of-day reconciliation, logging, alerting and a calm incident response.
- ·Live monitoring and dashboards
- ·Risk-limit alerts
- ·Trade and position reconciliation
- ·Logging and audit trails
- ·Incident response
- ·Post-mortems
A strategy that prints money in a backtest can still bankrupt you on a Tuesday afternoon. Not because the alpha vanished, but because a fill handler dropped a message and your system spent an hour trading a position it could not see. Or because a loss limit existed in a config file that nobody wired to an alert. The research is the glamorous half of quant; the unglamorous other half is operations - watching the live system, proving its books match the broker's, and having a calm, rehearsed answer for the moment something breaks. This chapter is about that half. It is the difference between a bad day and a blown-up account.
The monitoring loop
A live trading system is not fire-and-forget. The moment it places real orders it becomes a process you must watch, continuously, the way an operations desk watches a power grid. The core of that watching is a small set of numbers refreshed every few seconds: net P&L (realised plus mark-to-market), open positions by symbol, current exposure against your limits, order fill rates and rejects, data latency and feed staleness, and the simple heartbeat question - is the strategy process even alive?
The mistake beginners make is to monitor the strategy's opinion of the world (its internal P&L, its internal position) and nothing else. The whole point of a monitor is to catch the moment the system's opinion diverges from reality. So a good dashboard always shows two columns side by side: what we think, and what the venue says. When they agree, green. When they drift, you want to know in seconds, not at end-of-day settlement.
Risk-limit alerts
A limit you do not alert on is a comment, not a control. Every limit in your system - a per-strategy day-loss cap, a max position, a gross-exposure ceiling, a fat-finger order-size guard - needs a live check on every tick or every order, and a channel it screams down when crossed: a desk dashboard, a message to your phone, and ideally an automatic action like halting new orders or flattening.
The teaching example below monitors the simplest meaningful metric, running mark-to-market P&L, on a real RELIANCE session. We hold one lot (500 shares) from the open and set a hard intraday loss limit of Rs -2,500. The monitor watches the line, and on 25 June 2026 the position drifts down to a low of Rs -2,800 and trips the limit at 14:40. That single timestamp is the whole game: a risk control either fires the instant the threshold breaks, or it is theatre.
# Live monitoring: track a position's running P&L and trip an alert when the loss limit breaks.
import os
from datetime import datetime, timedelta
from pathlib import Path
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import seaborn as sns
from openalgo import api
client = api(
api_key=os.getenv("OPENALGO_API_KEY", "your_api_key_here"),
host=os.getenv("OPENALGO_HOST", "http://127.0.0.1:5000"),
)
# One real RELIANCE session of 5-minute bars; hold long 1 lot (500 sh) from the open.
end = datetime.now().strftime("%Y-%m-%d")
start = (datetime.now() - timedelta(days=6)).strftime("%Y-%m-%d")
bars = client.history(symbol="RELIANCE", exchange="NSE", interval="5m",
start_date=start, end_date=end)
day = bars.index[-1].date()
s = bars[bars.index.date == day]
QTY = 500
entry = s["close"].iloc[0]
pnl = (s["close"] - entry) * QTY # the monitored metric: running mark-to-market P&L
LIMIT = -2500 # hard intraday loss limit set by the risk monitor
breached = pnl[pnl <= LIMIT]
trip = breached.index[0] if len(breached) else None
sns.set_theme(style="whitegrid")
fig, ax = plt.subplots(figsize=(9, 4.6))
ax.plot(s.index, pnl, color="#7c83ff", lw=1.6, label="Running P&L")
ax.axhline(0, color="#9a9a9a", lw=0.9)
ax.axhline(LIMIT, color="#dc2626", lw=1.4, ls="--", label=f"Loss limit Rs {LIMIT:,}")
ax.fill_between(s.index, pnl, LIMIT, where=(pnl <= LIMIT), color="#dc2626", alpha=0.25)
if trip is not None:
ax.scatter([trip], [pnl.loc[trip]], color="#dc2626", zorder=5, s=40)
ax.annotate("ALERT: limit breached", (trip, pnl.loc[trip]),
textcoords="offset points", xytext=(8, -18), color="#dc2626", fontsize=9)
ax.set_title(f"RELIANCE intraday P&L monitor - long {QTY} sh, {day}")
ax.set_ylabel("Running P&L (Rs)")
ax.set_xlabel("Time")
ax.legend(loc="upper right", fontsize=8)
out = Path(__file__).with_suffix(".png")
plt.savefig(out, dpi=110, bbox_inches="tight")
trip_txt = trip.strftime("%H:%M") if trip is not None else "never"
print(f"Session {day}: P&L low Rs {pnl.min():,.0f}, limit Rs {LIMIT:,}, breached at {trip_txt}. Saved {out.name}")Session 2026-06-25: P&L low Rs -2,800, limit Rs -2,500, breached at 14:40. Saved 02_pnl_alert.png
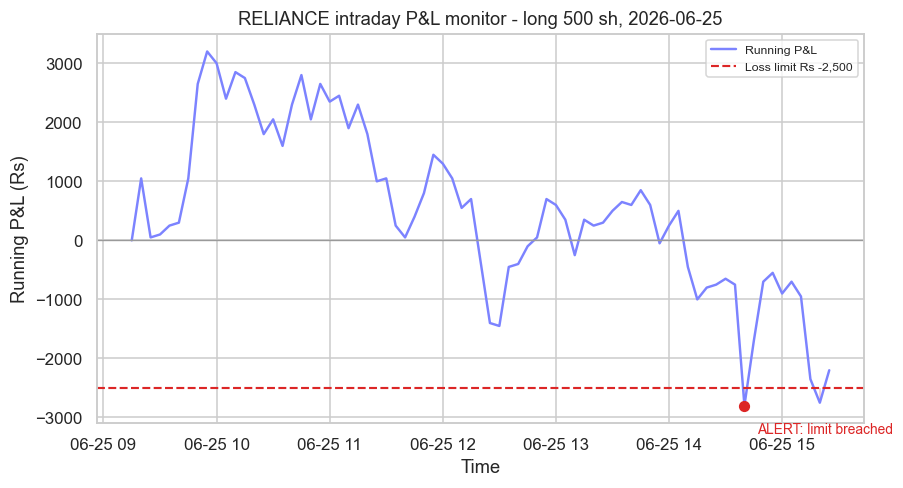
Set limits before the session, not in the heat of a drawdown. A loss limit you raise at 14:39 because you "feel" the position will come back is not a risk control - it is the exact behaviour the control exists to stop. Make limits hard, automated, and uncomfortable to override.
Reconciliation: trust, but verify
Here is the failure that quietly ends careers. Your strategy fires an order. The exchange fills it. The fill confirmation comes back over a socket - and your process is mid-garbage-collection, or the socket blipped, or a queue overflowed, and the message is lost. Your books now say you hold less than you actually do. Every downstream number - P&L, exposure, the next order's size - is computed against a position that does not exist. You are flying blind and you do not know it.
The defence is reconciliation: independently rebuild your position from your own record of fills, then compare it, line by line, against the broker's official position. Any difference is a break, and a break halts trading until a human understands it. The example builds an internal position from four recorded fills and compares it to the broker, who actually filled a fifth order our feed handler dropped. The internal book shows +1000 shares at a net cost of Rs 13,22,000; the broker shows +1500 shares; the system flags a +500-share break worth Rs 660,700 and recommends halting new orders and flattening on the broker's number, never our own.
# Reconciliation: rebuild position from your fills, compare to the broker, flag the break.
import os
from datetime import datetime, timedelta
from openalgo import api
client = api(
api_key=os.getenv("OPENALGO_API_KEY", "your_api_key_here"),
host=os.getenv("OPENALGO_HOST", "http://127.0.0.1:5000"),
)
# Real fill prices: take the first few 5-minute closes from the latest RELIANCE session.
end = datetime.now().strftime("%Y-%m-%d")
start = (datetime.now() - timedelta(days=6)).strftime("%Y-%m-%d")
bars = client.history(symbol="RELIANCE", exchange="NSE", interval="5m",
start_date=start, end_date=end)
day = bars.index[-1].date()
px = bars[bars.index.date == day]["close"].round(2).tolist()
# What our system THINKS happened: its own record of the day's fills (signed qty).
internal_fills = [
("BUY", 500, px[0]),
("BUY", 500, px[1]),
("SELL", 500, px[2]),
("BUY", 500, px[3]),
]
# What the BROKER actually filled: an extra 500-share buy our feed handler dropped.
broker_fills = internal_fills + [("BUY", 500, px[4])]
def net_position(fills):
qty = sum(q if side == "BUY" else -q for side, q, _ in fills)
cost = sum((q if side == "BUY" else -q) * p for side, q, p in fills)
return qty, cost
int_qty, int_cost = net_position(internal_fills)
brk_qty, brk_cost = net_position(broker_fills)
break_qty = brk_qty - int_qty
print(f"Session {day} symbol RELIANCE (NSE)")
print(f"Internal position : {int_qty:+5d} sh net cost Rs {int_cost:>12,.2f} ({len(internal_fills)} fills)")
print(f"Broker position : {brk_qty:+5d} sh net cost Rs {brk_cost:>12,.2f} ({len(broker_fills)} fills)")
print(f"RECONCILE BREAK : {break_qty:+5d} sh Rs {brk_cost - int_cost:>12,.2f} -> HALT new orders, investigate")
print(f"\nA {abs(break_qty)}-share break means one real fill never reached our books - flatten on the broker number, not ours.")Session 2026-06-25 symbol RELIANCE (NSE) Internal position : +1000 sh net cost Rs 1,322,000.00 (4 fills) Broker position : +1500 sh net cost Rs 1,982,700.00 (5 fills) RECONCILE BREAK : +500 sh Rs 660,700.00 -> HALT new orders, investigate A 500-share break means one real fill never reached our books - flatten on the broker number, not ours.
The broker is the source of truth for what you hold; your system is the source of truth for what you intended. Reconciliation is the discipline of proving those two agree - continuously through the day, not just at the close. When they disagree, the broker wins and you stop trading.
Real desks reconcile at three levels: trades (does every fill we recorded exist on the broker's trade book, and vice versa?), positions (does net quantity per symbol match?), and cash (does our P&L and ledger match the broker's, down to brokerage and charges?). Intraday reconciliation runs every few minutes against the broker's position book; an end-of-day reconciliation against the official contract notes is the final, authoritative check before you trust tomorrow's opening positions.
Logging and audit trails
You cannot reconcile, debug, or defend what you did not record. A production system writes an audit trail: every signal generated, every order sent with its parameters and timestamp, every acknowledgement, fill and reject, every risk-limit evaluation, every config value in force. The test of a good log is brutal and simple - can you reconstruct exactly what the system did, and why, at 14:40 on 25 June, from the logs alone? If not, the log is decoration.
Two properties matter. Logs must be timestamped precisely and consistently (one clock, ideally exchange-synced, so events from the feed, the strategy and the order gateway can be interleaved into one true sequence). And they must be immutable and complete - you never edit a log to make a bad day look better. Beyond your own debugging, this trail is also a regulatory requirement: under the SEBI retail-algo framework the audit trail of an algo's orders is exactly what an exchange or regulator can ask you to produce.
Log in a structured form (one event per line, machine-parseable fields) rather than free-text prose. A structured trail lets you replay a session, recompute P&L, and answer "show me every order this strategy sent between 14:30 and 14:45" with a one-line query instead of an afternoon of grep.
When it breaks: incidents and post-mortems
Things will break - a feed dies, a fill is lost, a limit trips, an order rejects in a loop. An incident is any of these, and a mature operation handles it with a rehearsed playbook rather than panic. The order of operations is almost always the same: stabilise first (halt new orders, then flatten or hedge the live risk using the broker's position, not your possibly-wrong internal one), then diagnose, then fix, then resume only once reconciliation is clean again. Stop the bleeding before you investigate the cut.
After the dust settles comes the post-mortem - a written, blameless account of what happened, the timeline from the logs, the root cause, and the concrete changes that stop a recurrence. Blameless matters: if engineers fear punishment they hide detail, and you lose the learning. The output is never "be more careful." It is a specific control: a new alert, a reconciliation that now runs every minute instead of every five, an idempotent fill handler that cannot drop a message. Every good control on a real desk is a fossil of a past incident.
The dropped-fill break in the example is a textbook incident trigger. The right response is not to argue with the broker's number but to trust it: halt, flatten 500 shares to match reality, then trace the logs to find which message the feed handler lost and why - and add the alert that would have caught it in seconds rather than at end-of-day.
Monitoring, reconciliation and incident handling are what separate a strategy that works from an operation that survives. They are the operational backbone beneath everything in Module I. With the system now built, watched and defended, the final two chapters step outside the code: the next on the SEBI rules and ethics that govern algo trading in India, and the capstone that ties the whole course together.